tbl(con, "read_parquet('geo.parquet')") |>
...
arrow::to_arrow() |>
arrow::write_dataset("mon_dataset")Pourquoi éviter arrow::to_arrow() avec DuckDB + dplyr
R
duckdb
arrow
Pourquoi utiliser
arrow::to_arrow est une mauvaise idée avec dplyr::tbl
Une syntaxe souvent recommandée pour écrire un fichier parquet après des ordres dplyr::tbl est d’utiliser arrow::to_arrow avec arrow::write_dataset ou arrow::write_parquet :
Cette syntaxe fonctionne toujours mais le nouveau package duckplyr propose une méthode beaucoup plus efficace :
- 1
-
converti l’objet retourné par
tblen objet lisible parduckplyr - 2
- écrit le fichier parquet
Les deux lignes fonctionnent de la même façon que celle de arrow en étant beaucoup plus efficace.
Une comparaison rapide
Voici les résultats de tests de différentes façons de faire classiques (et le code pour les relancer chez vous ci-dessous) :
-
with_arrow: la méthode utilisantarrow -
with_duckplyr: la méthode utilisantduckplyr -
with_copy_to: la méthode utilisant leCOPY ... TO ...deduckdbà titre de comparaison
Montre moi le code du benchmark
library(duckdb)
library(dplyr)
library(arrow)
# pour afficher
library(kableExtra)
# un outil de benchmark
library(timemoir)
if (!file.exists("geo.parquet")) {
download.file("https://static.data.gouv.fr/resources/sirene-geolocalise-parquet/20240107-143656/sirene2024-geo.parquet", "geo.parquet")
}
# la version full duckdb
with_copy_to <- function() {
con <- dbConnect(duckdb())
on.exit(dbDisconnect(con, shutdown = TRUE))
dbExecute(con, "COPY (FROM read_parquet('geo.parquet')) TO 'test.parquet' (FORMAT PARQUET, COMPRESSION ZSTD)")
}
# La version `"historique" avec `arrow` :
with_arrow <- function() {
con <- dbConnect(duckdb())
on.exit(dbDisconnect(con, shutdown = TRUE))
tbl(con, "read_parquet('geo.parquet')") |>
arrow::to_arrow() |>
arrow::write_dataset('test', compression='zstd')
}
# Et la même en utilisant le nouveau package duckplyr :
with_duckplyr <- function() {
con <- dbConnect(duckdb())
on.exit(dbDisconnect(con, shutdown = TRUE))
tbl(con, "read_parquet('geo.parquet')") |>
duckplyr::as_duckdb_tibble() |>
duckplyr::compute_parquet("my_tbl.parquet")
}res <- timemoir(
with_arrow(),
with_copy_to(),
with_duckplyr()
)res |>
kableExtra::kable()| fname | duration | error | start_mem | max_mem | cpu_user | cpu_sys |
|---|---|---|---|---|---|---|
| with_arrow() | 61.147 | NA | 149664 | 21835576 | 76.045 | 17.691 |
| with_copy_to() | 7.480 | NA | 149104 | 9096224 | 66.407 | 9.944 |
| with_duckplyr() | 7.013 | NA | 149104 | 11818744 | 54.990 | 10.564 |
plot(res)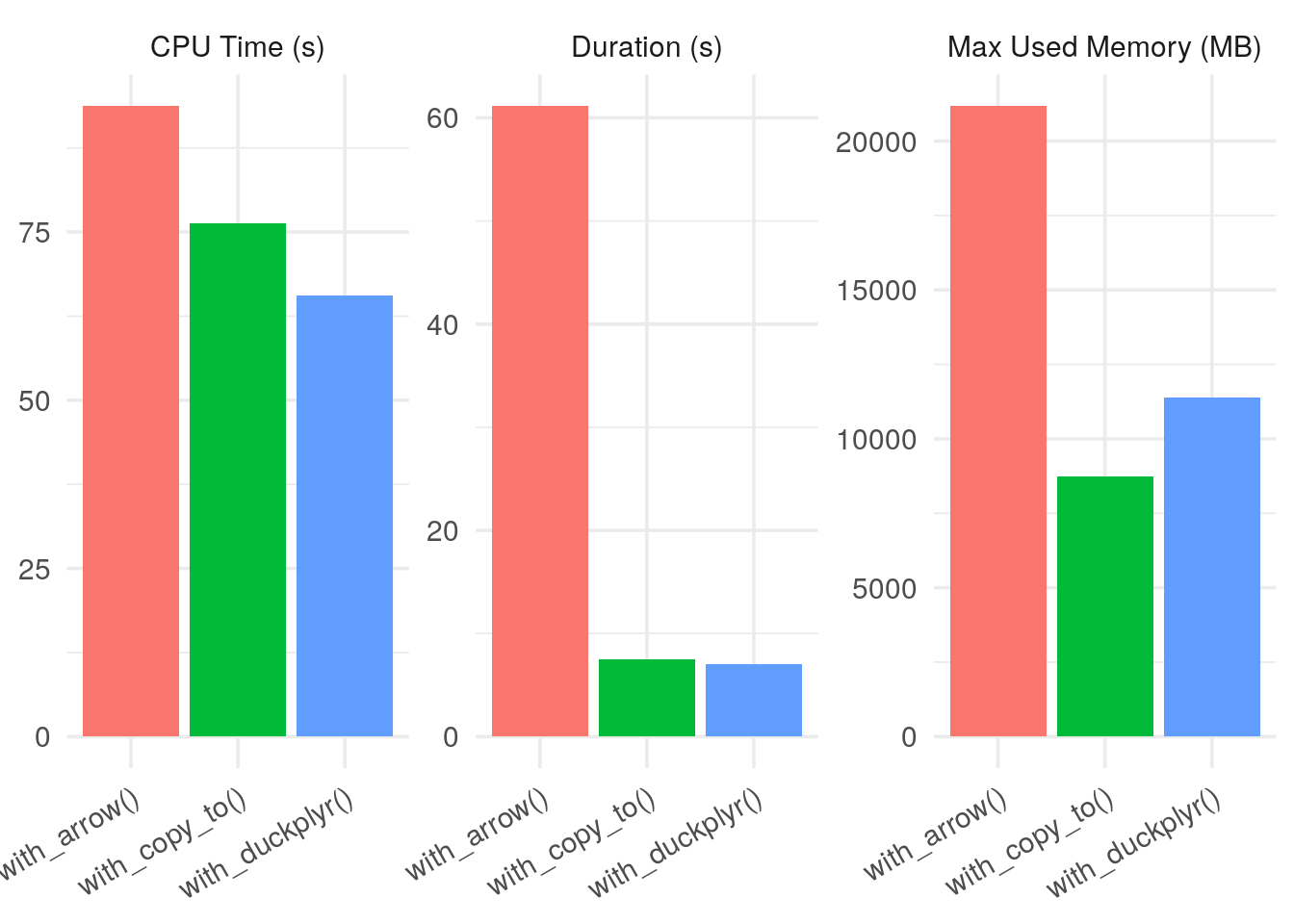
Sur le serveur que j’utilise, la version duckplyr est 6 fois plus rapide que la version arrow et consomme deux fois moins de mémoire, à égalité avec la méthode pure duckdb.
Conclusion
Si vous utilisez dplyr, arrêtez d’utiliser to_arrow et passez à duckplyr
Quelques liens
NoteInformation de session
devtools::session_info(pkgs = "attached")─ Session info ───────────────────────────────────────────────────────────────
setting value
version R version 4.5.0 (2025-04-11)
os Ubuntu 22.04.5 LTS
system x86_64, linux-gnu
ui X11
language (EN)
collate en_US.UTF-8
ctype en_US.UTF-8
tz Etc/UTC
date 2025-07-14
pandoc 3.7.0.2 @ /usr/bin/ (via rmarkdown)
quarto 1.7.31 @ /usr/local/bin/quarto
─ Packages ───────────────────────────────────────────────────────────────────
package * version date (UTC) lib source
arrow * 20.0.0.2 2025-05-26 [1] RSPM (R 4.5.0)
DBI * 1.2.3 2024-06-02 [1] RSPM (R 4.5.0)
dplyr * 1.1.4 2023-11-17 [1] RSPM (R 4.5.0)
duckdb * 1.3.0 2025-06-02 [1] RSPM (R 4.5.0)
kableExtra * 1.4.0 2024-01-24 [1] RSPM (R 4.5.0)
timemoir * 0.7.0.9000 2025-07-14 [1] Github (nbc/timemoir@01b6674)
[1] /usr/local/lib/R/site-library
[2] /usr/local/lib/R/library
* ── Packages attached to the search path.
──────────────────────────────────────────────────────────────────────────────