tbl(con, "read_parquet('geo.parquet')") |>
...
arrow::to_arrow() |>
arrow::write_dataset("my_dataset")Comparison between arrow::to_arrow() and duckplyr for writing Parquet files
R
duckdb
arrow
Why You Should Avoid arrow::to_arrow() with DuckDB + dplyr
A commonly recommended approach to write a Parquet file after using dplyr::tbl with duckdb is to use arrow::to_arrow with arrow::write_dataset or arrow::write_parquet:
While this syntax works, the new duckplyr package offers a much more efficient alternative:
- 1
-
duckplyr::as_duckdb_tibbleconverts the object returned bytbl()into aduckplyrobjet - 2
-
duckplyr::compute_parquetwrites the Parquet file
These two lines achieve the same result as the Arrow version, but using duckplyr is much more efficient.
A Quick Benchmark
Here are the results from benchmarking three common methods (with full reproducible code below):
-
with_arrow: usingarrow::to_arrow()+write_dataset() -
with_duckplyr: usingduckplyr::as_duckdb_tibble()+compute_parquet() -
with_copy_to: using DuckDB’s nativeCOPY ... TO ...as a baseline
Show me the benchmark code
library(duckdb)
library(dplyr)
library(arrow)
library(kableExtra)
library(timemoir)
if (!file.exists("geo.parquet")) {
download.file("https://static.data.gouv.fr/resources/sirene-geolocalise-parquet/20240107-143656/sirene2024-geo.parquet", "geo.parquet")
}
# Full DuckDB method
with_copy_to <- function() {
con <- dbConnect(duckdb())
on.exit(dbDisconnect(con, shutdown = TRUE))
dbExecute(con, "COPY (FROM read_parquet('geo.parquet')) TO 'test.parquet' (FORMAT PARQUET, COMPRESSION ZSTD)")
}
# "Historical" version with Arrow
with_arrow <- function() {
con <- dbConnect(duckdb())
on.exit(dbDisconnect(con, shutdown = TRUE))
tbl(con, "read_parquet('geo.parquet')") |>
arrow::to_arrow() |>
arrow::write_dataset('test', compression='zstd')
}
# Version using the new duckplyr package
with_duckplyr <- function() {
con <- dbConnect(duckdb())
on.exit(dbDisconnect(con, shutdown = TRUE))
tbl(con, "read_parquet('geo.parquet')") |>
duckplyr::as_duckdb_tibble() |>
duckplyr::compute_parquet("my_tbl.parquet")
}res <- timemoir(
with_arrow(),
with_copy_to(),
with_duckplyr()
)res |>
kableExtra::kable()| fname | duration | error | start_mem | max_mem | cpu_user | cpu_sys |
|---|---|---|---|---|---|---|
| with_arrow() | 125.123 | NA | 153200 | 21206428 | 157.164 | 50.598 |
| with_copy_to() | 28.969 | NA | 158720 | 11870840 | 157.578 | 58.525 |
| with_duckplyr() | 33.704 | NA | 164088 | 11933724 | 128.338 | 50.864 |
plot(res)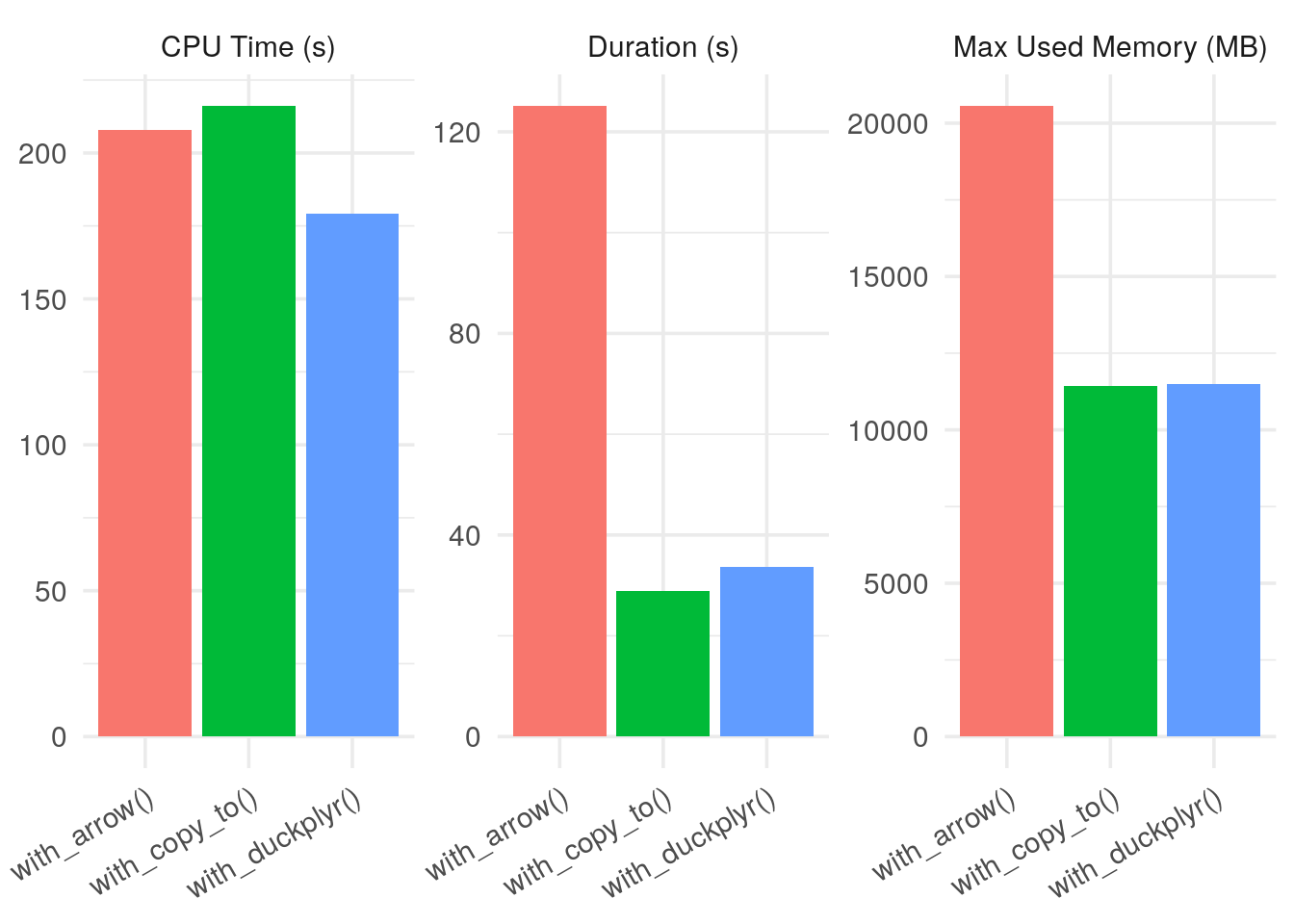
On the server I use, the duckplyr version is 9× faster than the arrow version and uses half the memory, performing on par with pure DuckDB (for this very simple test case).
Conclusion
If you’re working with dplyr, stop using to_arrow() and switch to duckplyr for better performance.
Useful Links
NoteSession Info
devtools::session_info(pkgs = "attached")─ Session info ───────────────────────────────────────────────────────────────
setting value
version R version 4.5.0 (2025-04-11)
os Ubuntu 22.04.5 LTS
system x86_64, linux-gnu
ui X11
language (EN)
collate en_US.UTF-8
ctype en_US.UTF-8
tz Etc/UTC
date 2025-08-09
pandoc 3.7.0.2 @ /usr/bin/ (via rmarkdown)
quarto 1.7.31 @ /usr/local/bin/quarto
─ Packages ───────────────────────────────────────────────────────────────────
package * version date (UTC) lib source
arrow * 20.0.0.2 2025-05-26 [1] RSPM (R 4.5.0)
DBI * 1.2.3 2024-06-02 [1] RSPM (R 4.5.0)
dplyr * 1.1.4 2023-11-17 [1] RSPM (R 4.5.0)
duckdb * 1.3.0 2025-06-02 [1] RSPM (R 4.5.0)
kableExtra * 1.4.0 2024-01-24 [1] RSPM (R 4.5.0)
timemoir * 0.8.0.9000 2025-08-09 [1] Github (nbc/timemoir@646734a)
[1] /usr/local/lib/R/site-library
[2] /usr/local/lib/R/library
* ── Packages attached to the search path.
──────────────────────────────────────────────────────────────────────────────